Every once and a while I will need to need to store a hierarchical structure in a database table. Recently, I needed to do this for a Facebook.com application I am building. In this particular application, I needed to categorize pieces of content in a hierarchical form, which a users can access by drilling down one level at a time. This blog details the solution I implemented on how to store the data and access it. Aren’t there are other articles on this? Yes, but their approach is typically very trivial and has issues when building out the application.
Included at the bottom of this blog entry is a zip of a sample application that demonstrates how to build product explorer using the technique described.
The problem statement!
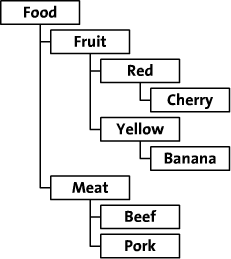
Below is the hierarchy of data that users can navigate through. Its a standard data structure that one would see in applications like; shopping carts, employee databases, and content management system.
- Books
- Non-fiction
- Politics
- Sports
- Non-fiction
- Electronics
- TV
- Speakers
- Computers
- Cars
- Dodge
- Magnum
- Nitro
- Chevy
- Dodge
Each category can have sub categories and/or products, take for instance the sample above; “Books” has a sub category called “Non-fiction” which has two sub categories. Not shown in the data above is that each category has a set products it is holding, for instance:
- Politics
- “Politics for Dummies”
- “Student Atlas of World Politics”
- Magnum
- 2007 STX mint condition
How do I store the information in a database table that has just rows and columns?
- I need to be able to perform the following operations; insert, update, delete, and select.
- The solution should be easy to create. Little code that is easy to understand.
- The solution needs to be easily stored in a database.
- Selection of items needs to be possible with SQL.
- Inserting and updating a record should affect no other data in the database.
- Delete should only affect the deleted item and its descendants.
A non optimal approach?
I have read a few articles on approaches to solve this problem and each one has a number of drawbacks that makes their approach hard to deal with when actually building out the application.
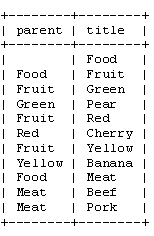
One approach is to use the name of the parent as the column in the database.
| parent | name |
|---|---|
| Books | |
| Electronics | |
| Cars | |
| Cars | Dodge |
| Books | Non-fiction |
| … | |
This seems simple, logical and will work but once you start to build the application you will notice a major short coming. You loose any ancestorial information other than the parent. This may not seem like a big deal - I know my parent, so I can find their parent. True. The real problem comes in the complexity of the code you are going to need; recursion or other to trace one’s roots.
A couple questions you way name want to know quickly and easily that make ancestorial information important. How many products do me or my descendants have? Where would you use this? Display the number of products contained below a category “Books (2)” based on the information above.
Another issues is what happens if the name of the category changes; “Cars” now becomes “Automobiles” because marketing thinks it sounds more sophisticated - meaning - intelligently appealing - I looked it up. This can easily be resolved by using the id of the parent, or updating all items that have a certain parent when the name changes.
| id | parent | name |
|---|---|---|
| 1 | Books | |
| 2 | Electronics | |
| 3 | Cars | |
| 4 | 3 | Dodge |
| 5 | 1 | Non-fiction |
| … | ||
Above is what the data would look like using the id of the parent in the parent column. This solves the name change issue but still has the ancestry problem of the above solution.
There are also other solutions that store the location in the tree, who is to the left and to the right of me. But this solution again is difficult to manage and code against when developing an application.
These solutions fail a few of the solutions requirements.
- Fails - The solution should be easy to create. Little code that is easy to understand. You will need to use recursion which is slow and can be complicated.
- Fails - Inserting and updating a record should affect no other data in the database. When using the left and right approach you will need to adjust the data for other rows of the database outside the affected rows.
- Fails - Delete should only affect the deleted row and its descendants. As above you will need to adjust the left and right when changing the structure of the tree
Resources on this approach:
http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
http://www.sitepoint.com/article/hierarchical-data-database
http://www.sitepoint.com/article/hierarchical-data-database
So what is the best way to do this?
In a past life, I developed network management software, which had many complicated problems that need solutions. TCP, UDP, SMNP, MIB were all acronyms that you needed to know in order to get the job done.
Most of the applications displayed data queried from a network device. Accessing the information was done by requesting data based on an OID. OIDs are simply a string in dot-notation for a specific piece of information. To pull the “device name” you would ask for OID “1.3.6.1.2.1.1.5″.
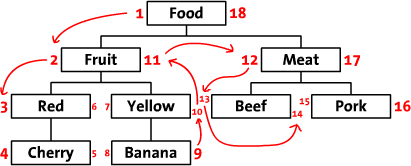
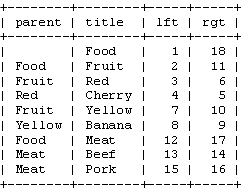
So what does this have to do with this article? Everything. The OID was the way to flatten the data which is hierarchical. How would you use this in our category sample? The picture below shows the data displayed with the parent being the “OID” of the parent node.

The root items “Books”, “Cars”, and “Electronics” have a parent which is empty to denote they are a root. All other items have parent value equal to id of all parent’s separated by a “.”.
Lets see how this solution works against the list of requirements:
- I need to be able to perform the following operations; insert, update, delete, and select.
- Included in the sample is code to perform all of the functionality that is needed to; insert, update, delete and select the data.
- The solution should be easy to create. Little code that is easy to understand.
- Solution is very easy; each operation is no more than two database operations and contains no recursion or rebuilding of the database.
- The solution needs to be easily stored in a database.
- The parent information is stored in a single column in the database as alphanumeric characters.
- Selection of items needs to be possible with SQL.
- Selecting a category or product is done with a simple equality operator. Selection of descendants is done in MySQL with the “LIKE” operator.
- Inserting and updating a record should affect no other data in the database.
- In the sample, look at the “insert.php” and “update.php” to see how to perform this functions.
- Delete should only affect the deleted row and its descendants.
- In the sample, look at the “delete.php” file to see how to delete both a category and a leaf (product) from the database
A couple questions that you might have:
Is this hard to work with?
- Actually it is very easy. In the sample application, I have functionality for adding, updating, deleting and selecting categories and products as well as displaying a bread crumb of the ancestors (This could also be used to display a breadcrumb trail and make them links in any website).
- You just need this parent’s database record to create the child record.
- Can delete all descendants easily.
- Updating the record requires just the id of the element.
- Less columns using other left and right techniques
How do I create the parent column?
- The parent id is created using the following code:
$parentPrefix = $currentCategoryRecord[”parent”];
if ($parentPrefix != null){
$parentPrefix .= $currentCategoryRecord[”id”].”.”;
}else{
$parentPrefix = $currentCategoryRecord[”id”].”.”;
}
This code creates the parent prefix for the currently displayed category and is need only to query descendants.
How do you find all the categories in a certain category?
- “SELECT * FROM product_table where parent=’”+
+”‘” in the data pictured above, if I want to display the categories TVs the select statment would look like “SELECT * FROM product_table where type=1 AND parent=’11.13.’
Why the “.” at the end of the parent?
- This makes it possible to distinguish between a category that starts with “1″ and a category that starts “11″. Not have the ending “.” means a startswith(’1′) or “WHERE parent LIKE ‘1%’ will find both “1″ and “11″ to be the ancestor.
Why not just combine the id and parent fields?
- By having two separate fields the data can be inserted into the database using a single statement. If they were a single field you would need to find the highest numbered product or category already entered at that level and increment it by one before inserting the new record.
- By having two fields, the “id” column can be a simple auto incrementing integer which can be joinde with other tables of data.
How do you tell what level a node is at?
- Using the PHP split function you can just capture the level:
$level = count(split($parent) ) - 1; In the sample I display a breadcrumb trail for the currently selected category. It is very simple use the split function and select all the ancestors from the database based on the id.
Why is there a type column?
- In my sample application, I am storing both categories (Tree Nodes) and products (Leafs). The type field differentiates the tree nodes from the leafs. In another application is may demote folders and files.
How do I find how many products a node or its descendants have?
- Determining how many products are under a node is performed by using a single SQL query on the database. “SELECT COUNT(id) as count from product_table where parent LIKE ‘
%’.
Isn’t the “LIKE” operator a performance hog?
- Performance is something that may take a slight hit, but only slightly. I did a bunch of research on this and found a good resource on using the “LIKE” operator. Click here to read a write up by John Nelsonhttp://myitforum.com/cs2/blogs/jnelson/archive/2007/11/16/108354.aspx
- You also reduce the number of queries need overall and you never need to rebuild the tree if the structure changes.
Content Copied from http://www.rockstarapps.com/wordpress/?p=82